Catalog Import
|
This documentation is not for the latest version Pacemaker version. Click here to switch to version 1.2 |
The catalog import is one of the predefined pipelines (What is a pipeline?), which you can use after installing Pacemaker. There are sample files, which can be used as a template for your own data files or for testing purposes (see Run your first predefined import jobs). On this page, you will read how it works, how to configure, and how to customize this pipeline.
Pipeline Definition
The catalog import pipeline is designed to import the whole catalog data at once. Therefore attributes, attribute-sets, categories and products need to be handled in the same pipeline. However, all of these import steps are optional and it depends on the given files, whether this data will be imported or not.
The import pipeline contains the following steps:
| Stage | Step | Description |
|---|---|---|
Prepare |
move_files |
Move import files to the working directory of the current pipeline |
Transformation |
product_transformation |
This step has a dummy executor in default and is designed in order to customize for mapping and transformation purpose |
Pre-Import |
index_suspender_start |
Activates delta index suspending in order to avoid cron based re-indexing during the import |
Attribute Set Import |
attribute_set_import |
Create/Update attribute sets |
Attribute Import |
attribute_import |
Create/Update attributes |
Category Import |
category_import |
Create/Update categories |
Product Import |
product_import |
Create/Update products |
Post-Import |
index_suspender_stop |
Disable suspending of delta indexers |
Configuration
In Magento’s backend (admin-ui) you’ll find settings for the catalog import under following path:
Stores > Configuration > TechDivision > Pacemaker Import > Catalog Import
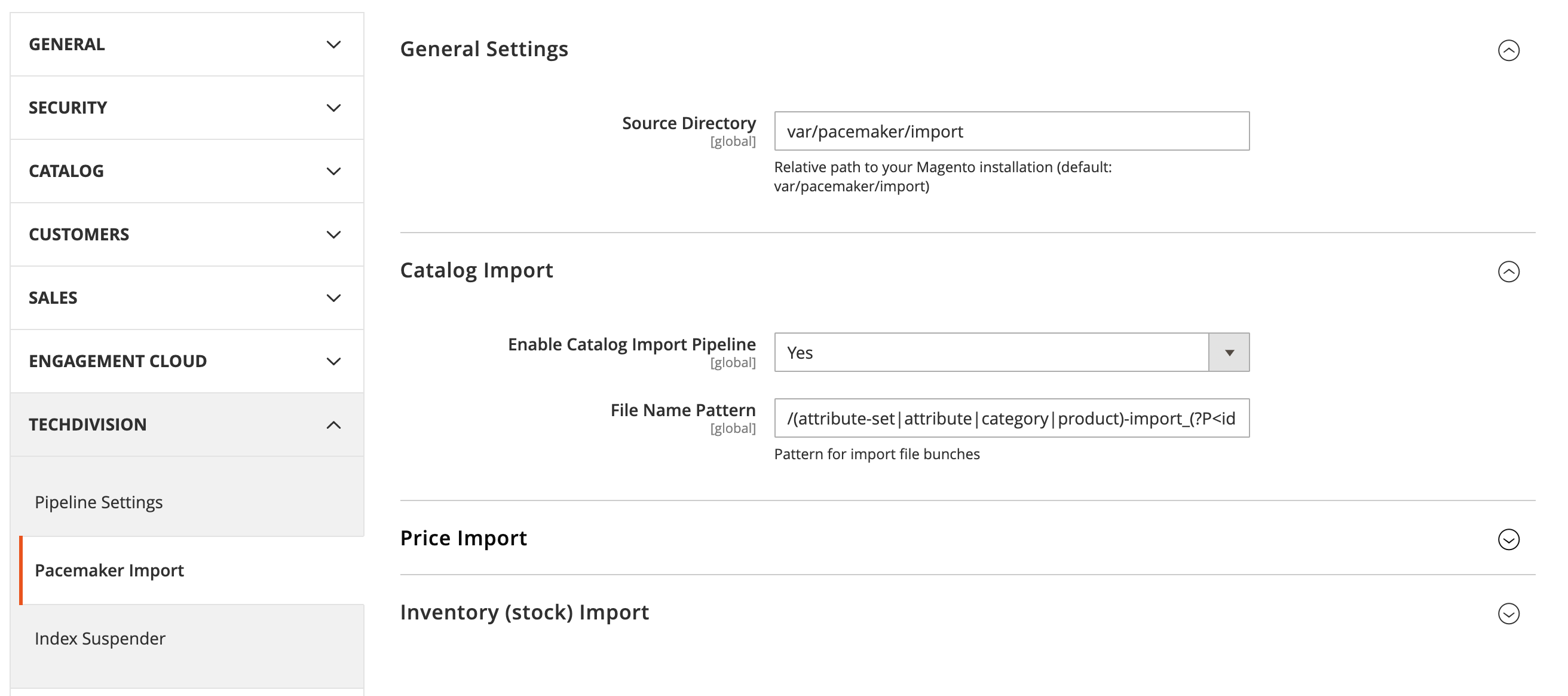
| Configuration | Description | Default Value |
|---|---|---|
General Settings > Source Directory |
Defines the source directory for import files. This directory will be observerd by Pacemaker in oder to intialize a import pipeline. This setting is for all pacemaker imports. |
|
Catalog Import > Enable Catalog Import Pipeline |
Active toggle for the source directory observer for catalog import. |
Yes |
Catalog Import > File Name Pattern |
Regular expression, which defines the source file name for source directory observer. |
|
Import Files Observer (How it works)
The observer for import files is also a pipeline. The condition
TechDivision\PacemakerImportCatalog\Virtual\Condition\HasImportBunches uses the configuration
Catalog Import > File Name Pattern in order to detect importable file bunches. If there are some
in the source directory, the step init_import_pipeline will create a new import pipeline for each bunch of files.
What is a file bunch?
Since Pacemaker is using M2IF it is possible to split all import
files into multiple files. And because Pacemaker is running attribute-set, attribute, category and product
import in one pipeline a bunch could grow to a big number of files. All these files need the same identifier in
the file name. This identifier is defined in the File Name Pattern configuration within this part of the
regular expression (?P<identifier>[0-9a-z\-]*).
According to the default expression, the filenames need to be in the following pattern:
<IMPORT_TYPE>-import_<BUNCH_IDENTIFIER>_<COUNTER>.<SUFFIX>. There are example files provided in
Pacemaker packages, please refer to
Run your first predefined import jobs.
Of course, you can change the expression if necessary, just take care to define an identifier
within the pattern.
Examples
The following files would result in one import pipeline because the identifier is the same
for all files. Also, only the steps attribute and product import would be executed. Attribute-set
and category import would be skipped because there are no files given.
- attribute-import_20190627_01.csv
- attribute-import_20190627.ok
- product-import_20190627_01.csv
- product-import_20190627_02.csv
- product-import_20190627_03.csv
- product-import_20190627.okThe following files would result in two import pipelines, while the first bunch import all entities and the second bunch imports only product data.
- attribute-set-import_20190627-1_01.csv
- attribute-set-import_20190627-1.ok
- attribute-import_20190627-1_01.csv
- attribute-import_20190627-1.ok
- category-import_20190627-1_01.csv
- category-import_20190627-1.ok
- product-import_20190627-1_01.csv
- product-import_20190627-1_02.csv
- product-import_20190627-1_03.csv
- product-import_20190627-1.ok
- product-import_20190627-2_01.csv
- product-import_20190627-2_02.csv
- product-import_20190627-2_03.csv
- product-import_20190627-2.ok